@Hack CTF - impressions and ENIPTX (RE 500) writeup
Recently p4 team (which includes a few of our coworkers) was invited to play the @Hack CTF Final - a CTF organized during @Hack conference in the capital of Saudi Arabia - Riyadh. The event was organized by Saudi Federation for Cybersecurity, Programming and Drones in cooperation with the Black Hat. It was the first major on-site CTF in which we could participate since the start of the COVID-19 pandemic. That was very exciting news! The organizers invited the top 15 teams from last year's CTFtime ranking. Additionally, organizers of @Hack decided to reimburse all travel costs for international teams, which was enough to convince us to fly over and try our best. All in all, we ended up securing 3rd place right after DiceGang (2nd) and r3billions (1st).

When we arrived at King Khalid International Airport, we were instantly greeted by the organizers and guided to relax at the VIP lounge, which was really pleasing and beyond our expectations. The hotel we were staying at, to our surprise, turned out to be Hilton Honors hotel, where each of us had their own room.

We didn't have much time to attend the conference talks, but just with a glance we knew they were on the top level. Anyone could find a talk for themselves, ranging from novel DevOps ideas, though attacking large Terraform infrastructures, to the newest Windows pwns. And that's just the tip of the iceberg!
The CTF itself was divided into 3 days, the first two being around 8 hours and the final one around 4 hours, where each day had its own set of challenges from different categories: re, web, crypto, pwn, osint, forensics, misc.

After the CTF, we obviously spent some time sightseeing. That's the biggest perk of on-site CTFs - not only do you get to travel, but you can stay a while after the CTF. Among many tourist attractions, we were especially impressed by the ancient At-Turaif district.

Overall this was a fantastic trip. We thank the organizers and hope to revisit Saudi in the future.
Below, you'll find our solution to one of the reverse engineering challenges from @Hack CTF Final.
ENIPTX - RE500 Writeup
The challenge was called ENIPTX and was worth 500 points (the CTF used a unusual mix of static and dynamic scoring) since it was in the "Insane" category. We haven't solved the challenge during the CTF, as it was released on the final day, so we had only 4 hours. It didn't seem to be quickly solvable, so we moved on to other challenges. But today, we're re-visiting the challenge!
We're given a single x64 Windows binary named ENIPTX.exe. When run, it waits for input, then prints "Acess Denied" (this is not a typo, there is only 1 "c" in the string) and exits. It seemed to be a "password checker" type of reverse engineering challenge. The trick is that there doesn't seem to be "Acess Denied" string anywhere! We popped the binary into the IDA Pro and quickly found an interesting bit.
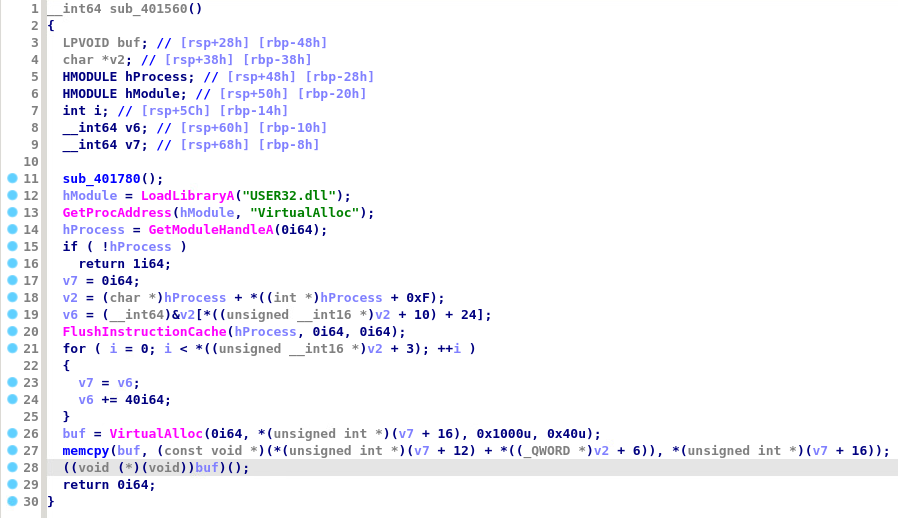
This function allocates a buffer, copies some data to it, and performs call rax to transfer execution not to a fixed address, but to a register. This usually means that destination is not known during compile time, instead it's dynamically obtained during execution. Since we're trying to acquire unpacked code, we'll follow this trail.
Note: if you plan on following these steps - use hardware breakpoints instead of regular ones, as this challenge uses certain anti-debug techniques.
What we've found in the allocated buffer is this:
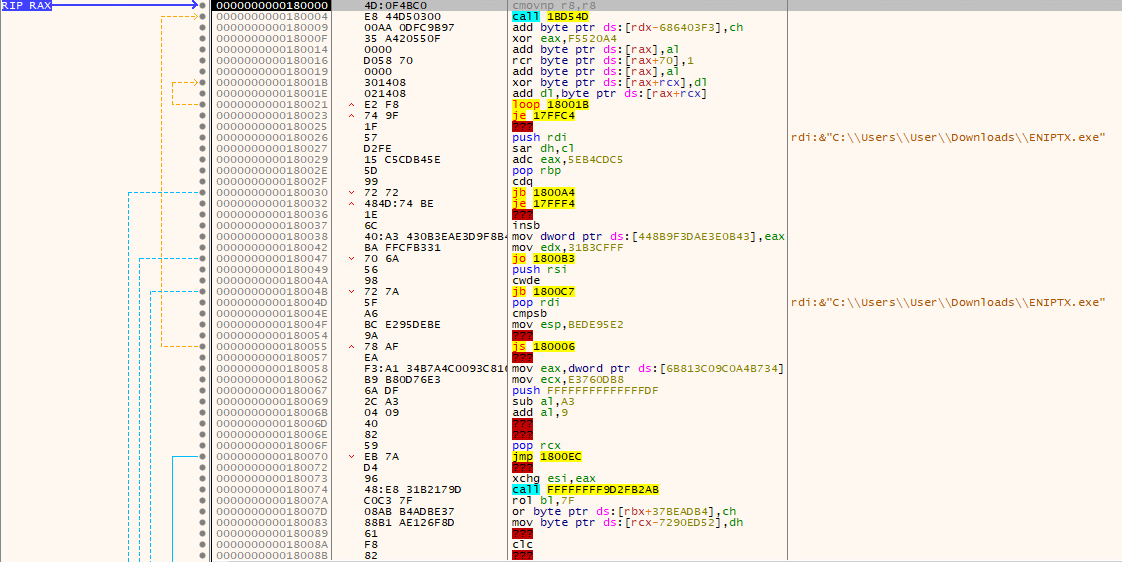
The first ~11 instructions look "OK", but the following opcodes are garbage, so at this stage there isn't anything worth importing into the IDA for static analysis. However, there is a XOR loop (addresses 0x18001B to 0x180021) just before the invalid instructions.
Let's put a breakpoint right after the loop and let the program run:
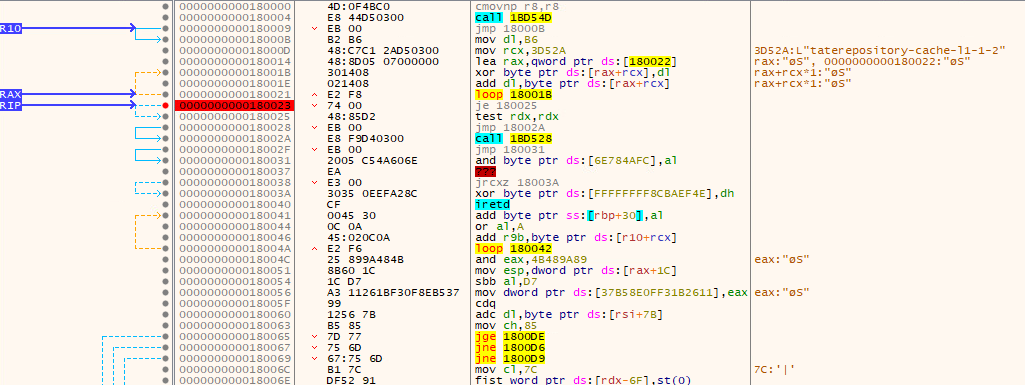
We can see that opcodes following this loop have changed. The call 18BD528 jumps to the next XOR loop. This resembles a very simple packer.
This pattern of XOR loop decrypting next part of the payload repeats a few times. Luckily for us, the amount of encrypted layers isn't too high, so we can unpack it by hand. First, we step into the XOR loop with a debugger, place a (hardware!) breakpoint right after the loop and finally let the program resume. After just a few layers, we get to the main unpacking part:
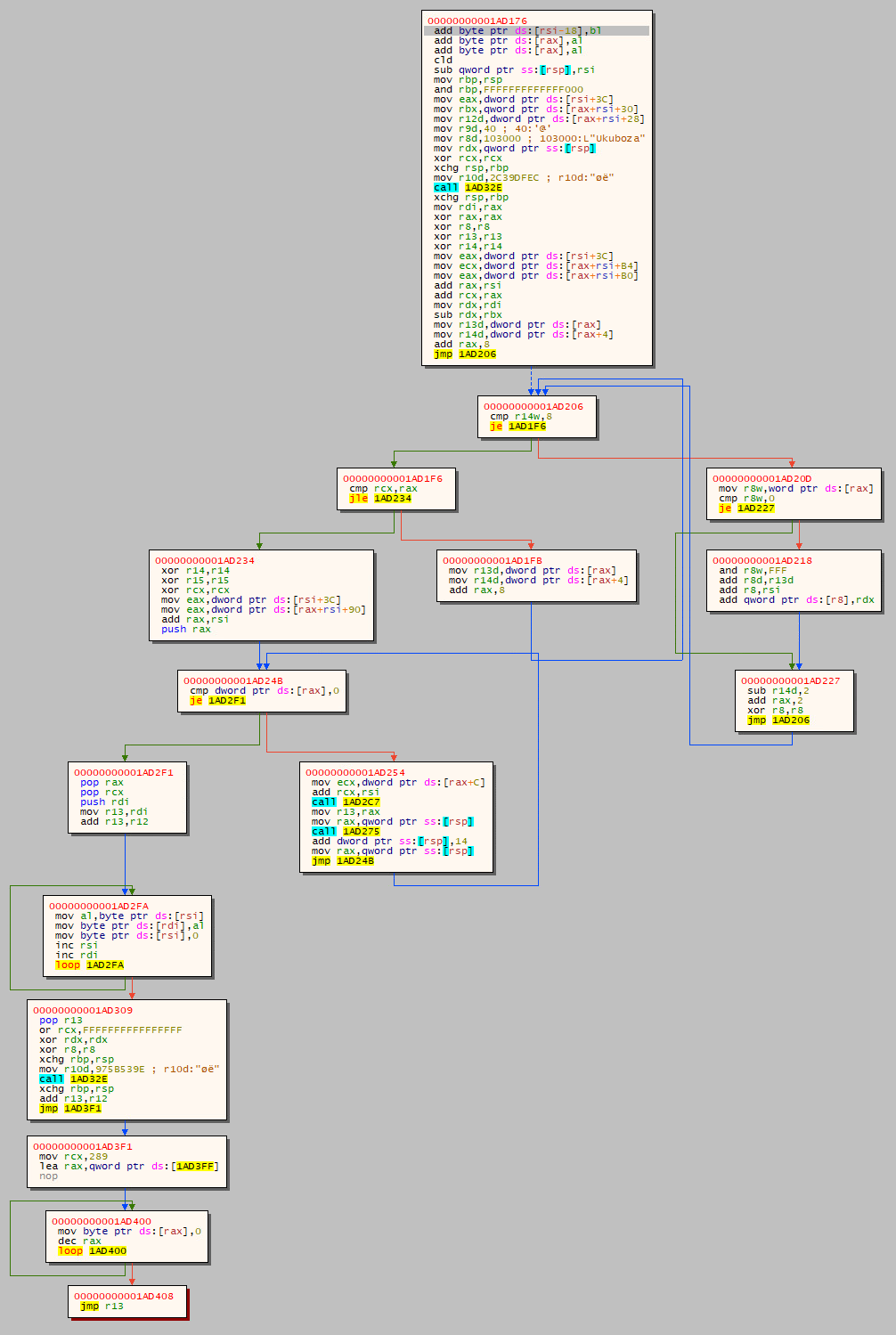
On the right side, we can see the import resolver routine. As it wasn't crucial for the challenge, we didn't analyze it further. The code takes a list of function names and resolves them into function pointers. If you wish to see how it works, put a (hardware!) breakpoint on the GetProcAddress function. What's interesting for us is the jmp r13 at the end. Let's inspect where r13 register points. As we mentioned earlier, time was very limited during the CTF, so we decided to go with the naive and easy way - dynamically dump the new section.
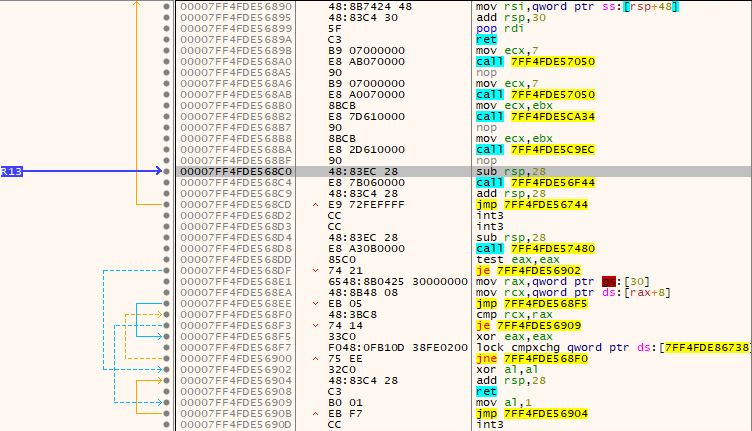
This does look like proper assembly code. Let's dump this new memory region (in x64dbg you can do that by right-click => "follow in memory map", which will switch view and highlight memory region you're looking for, to dump it right-click => "dump memory to file") and load it in the IDA. Remember to save the base address, otherwise you'll get garbage. Here you have our dump - eniptx_00007FF4FDE50000.bin.
However, if we attempt to decompile the entry point of this newly loaded section, we'll get an error:

This is caused by stack manipulation. There is a standard prologue of sub rsp, 28h, but at the end, we see add rsp, 28h followed by jmp. Usually, a return address is stored on the stack and ret instruction pops it, but since there's no ret instruction IDA doesn't know what to do with the stack and decompilation fails. To deal with it, we could patch opcodes and fix this. Although, we have to remember that our goal is to get the flag. Let's take some shortcuts and just search for the "Acess Denied" string in the newly dumped section.

It exists right next to "Acess Granted!" string. Bingo! There's even an xref to a function. I've renamed it to todo_win. This function even properly decompiles!
__int64 __fastcall todo_win()
{
signed __int64 v0; // rax
char *v1; // rsp
__int64 index; // rbx
__int64 v3; // rcx
__int64 v4; // r8
unsigned __int64 str_len; // rax
int cur_len; // esi
__m128i *p_mod_user_input_1; // r14
unsigned __int64 bytes_left; // rax
unsigned __int64 bytes_to_copy; // r8
char *p_user_input; // rdx
int *errno; // rax MAPDST
const char *mby_user_input; // rdi
int v14; // eax
__int64 capacity; // rcx
__int64 i; // rsi
int rand; // edi
uint32_t *key_ptr; // rdi
int v19; // er8
int v20; // er9
int v21; // er10
int v22; // er11
uint32_t v23; // eax
__int64 v24; // rcx
__int64 v25; // r8
__int64 v26; // rcx
__int64 v28; // [rsp+0h] [rbp-100h] BYREF
char *EndPtr; // [rsp+38h] [rbp-C8h] BYREF
char *user_input; // [rsp+40h] [rbp-C0h] BYREF
unsigned __int64 mby_str_len; // [rsp+50h] [rbp-B0h]
unsigned __int64 v32; // [rsp+58h] [rbp-A8h]
string String; // [rsp+60h] [rbp-A0h] BYREF
unsigned __int64 v34; // [rsp+78h] [rbp-88h]
__m128i scratchpad_1; // [rsp+80h] [rbp-80h] BYREF
__m128i scratchpad_2; // [rsp+90h] [rbp-70h]
__m128i target_1; // [rsp+A0h] [rbp-60h] BYREF
__m128i target_2; // [rsp+B0h] [rbp-50h]
__m128i mod_user_input_1; // [rsp+C0h] [rbp-40h] BYREF
__m128i mod_user_input_2; // [rsp+D0h] [rbp-30h] BYREF
int32_t matrix[4][256]; // [rsp+E0h] [rbp-20h] BYREF
unsigned __int64 cannary; // [rsp+20F0h] [rbp+1FF0h]
v1 = (char *)alloca(v0); // 0x2100
cannary = (unsigned __int64)&v28 ^ qword_7FF4FDE85020;
index = 0i64;
user_input = 0i64;
mby_str_len = 0i64;
read_user_input(&stdin, &user_input);
target_1 = _mm_load_si128(&xmmword_7FF4FDE804B0);
target_2 = _mm_load_si128(&xmmword_7FF4FDE804C0);
sub_7FF4FDE58AF0(matrix, 0, 0x2004ui64);
mod_user_input_1 = 0i64;
mod_user_input_2 = 0i64;
str_len = mby_str_len;
if ( mby_str_len != 32 )
{
stl_some_print(v3, (__int64)aAcessDenied, v4);
sub_7FF4FDE5CA34(1u);
__debugbreak();
}
// *snip uninteresting code that copies input from user_input into mod_user_input_1 + mod_user_input_2*
scratchpad_1 = _mm_load_si128(&xmmword_7FF4FDE804E0);
scratchpad_2 = _mm_load_si128(&xmmword_7FF4FDE804D0);
srand(0x21F020C9u);
for ( i = 0i64; i < 8; ++i )
{
rand = ::rand();
scratchpad_1.m128i_u32[i] += ::rand() * rand;
}
gen_matrix(matrix, target_1, scratchpad_1);
// first round of mangling
xor_lookup(
mod_user_input_2 + 3,
-4,
target_1.m128i_u32,
scratchpad_1.m128i_u32,
(int32_t (*)[4][256])matrix);
// second round of mangling
key_ptr = (uint32_t *)&mod_user_input;
v19 = '5QDy';
v20 = 'DH79';
v21 = '022Z';
v22 = 'FbUr';
do
{
v23 = v22 ^ *key_ptr;
*key_ptr++ = v23;
v19 = matrix[0][(unsigned __int8)(v23 + v19)] ^ ((v23 + v19) >> 8) & 0xFFFFFF;
v20 = matrix[1][(unsigned __int8)(v19 + v20)] ^ ((v19 + v20) >> 8) & 0xFFFFFF;
v21 = matrix[2][(unsigned __int8)(v20 + v21)] ^ ((v20 + v21) >> 8) & 0xFFFFFF;
v22 = matrix[3][(unsigned __int8)(v21 + v22)] ^ ((v21 + v22) >> 8) & 0xFFFFFF;
}
while ( (((char *)key_ptr - (char *)matrix) & '\xFC') != 0 );
// third round of mangling
xor_lookup(
mod_user_input_2 + 3,
-8,
target_1.m128i_u32,
scratchpad_1.m128i_u32,
(int32_t (*)[8][256])matrix);
// mangled input comparison with constant factors
target_1 = _mm_load_si128(&target_cmp1);
target_2 = _mm_load_si128(&target_cmp2);
do
{
if ( mod_user_input.m128i_u32[index] != target_1.m128i_u32[index] )
{
stl_some_print(v24, aAcessDenied, v25);
sub_7FF4FDE5CA34(0);
std::_Xlength_error(aStoiArgumentOu);
}
++index;
}
while ( index < 8 );
stl_some_print(v24, aAcessGranted, v25);
// *snip uninteresting code*
return 0i64;
}
Let's summerize what we can see this function does:
- reads input from the user,
- expects length of the input to be 32 bytes,
- loads
key(namedtarget, since same memory region is reused at the end) andscratchpadvariables from constants, - generates a matrix,
- performs 3 mangling operations on user input,
- compares the outcome of those operations with constant byte array.
By quickly skimming over the implementation of the gen_matrix function, we can deduce that generated matrix is constant and doesn't depend on user input. This is further confirmed by dynamic analysis. At this point, we've attempted to cheese our way past reversing the rest of this function by using angr, but sadly it didn't work (after hours of calculations, angr fell into a recursive loop and failed to calculate the flag). It was worth a try, though.
Let's see what the xor_lookup function looks like:
__int64 __fastcall xor_lookup(int *user_input, int offset, int *key, int *output, int32_t (*matrix)[8][256])
{
int v5; // er11
int *input_iter; // r15
int v7; // ebx
int v8; // edi
int v9; // er10
int v10; // esi
int v11; // ebp
int v12; // er14
int v13; // er8
int *input_ptr; // r13
__int64 result; // rax
int v16; // eax
int v17; // er11
v5 = key[0];
v7 = key[1];
v8 = key[2];
v9 = key[3];
v10 = key[4];
v11 = key[5];
v12 = key[6];
v13 = key[7];
input_iter = user_input;
input_ptr = &user_input[offset];
result = -4i64 * offset;
if ( result )
{
do
{
v16 = *input_iter ^ v9;
*input_iter = v16;
v17 = v16 + v5;
input_iter += (int)(((offset >> 31) & 0xFFFFFFFE) + 1);
result = (char *)input_iter - (char *)input_ptr;
v5 = (*matrix)[0][(unsigned __int8)v17] ^ (v17 >> 8) & 0xFFFFFF;
v7 = (*matrix)[1][(unsigned __int8)(v5 + v7)] ^ ((v5 + v7) >> 8) & 0xFFFFFF;
v8 = (*matrix)[2][(unsigned __int8)(v7 + v8)] ^ ((v7 + v8) >> 8) & 0xFFFFFF;
v9 = (*matrix)[3][(unsigned __int8)(v8 + v9)] ^ ((v8 + v9) >> 8) & 0xFFFFFF;
v10 = (*matrix)[4][(unsigned __int8)(v9 + v10)] ^ ((v9 + v10) >> 8) & 0xFFFFFF;
v11 = (*matrix)[5][(unsigned __int8)(v10 + v11)] ^ ((v10 + v11) >> 8) & 0xFFFFFF;
v12 = (*matrix)[6][(unsigned __int8)(v11 + v12)] ^ ((v11 + v12) >> 8) & 0xFFFFFF;
v13 = (*matrix)[7][(unsigned __int8)(v12 + v13)] ^ ((v12 + v13) >> 8) & 0xFFFFFF;
}
while ( (((char *)input_iter - (char *)input_ptr) & 0xFFFFFFFFFFFFFFFCui64) != 0 );
}
output[0] = v5;
output[1] = v7;
output[2] = v8;
output[3] = v9;
output[4] = v10;
output[5] = v11;
output[6] = v12;
output[7] = v13;
return result;
}
The first thing we thought when we first decompiled this function - it looks awkwardly close to the second mangling stage (keep this in mind for later). With this knowledge, the challenge is already solvable, but requires quite a lot of experience in these types of challenges. To make it easier, we can set up a breakpoint right after the call to gen_matrix and dump the memory section with the already generated matrix (our dump is accessible here - eniptx_000000000064A000.bin).
Below we've highlighted:
output- redkey- blueuser_input- greenmatrix- yellow
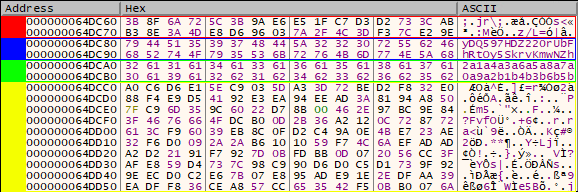
Since decompiled code is sometimes hard to comprehend, let's rewrite it to Python, to clarify what's happening.
from pwn import u32, group, unhex, hexdump
from typing import List
output: List[int]
key: List[int]
user_input: List[int]
matrix: List[List[int]]
def b(val: int) -> int:
"""cast to byte"""
return val & 0xFF
def d(val: int) -> int:
"""cast to dword"""
return val & 0xFFFFFFFF
def xor_lookup(first_pass: bool) -> None:
v1, v2, v3, v4, v5, v6, v7, v8 = key
if first_pass:
end = 3
else:
end = 0
for i in range(7, end, -1):
old = user_input[i]
new = old ^ v4
user_input[i] = new
v17 = new + v1
# 0xFFFFFF not dword
v1 = matrix[0][b(v17)] ^ ((v17 >> 8) & 0xFFFFFF)
v2 = matrix[1][b(v1 + v2)] ^ (((v1 + v2) >> 8) & 0xFFFFFF)
v3 = matrix[2][b(v2 + v3)] ^ (((v2 + v3) >> 8) & 0xFFFFFF)
v4 = matrix[3][b(v3 + v4)] ^ (((v3 + v4) >> 8) & 0xFFFFFF)
v5 = matrix[4][b(v4 + v5)] ^ (((v4 + v5) >> 8) & 0xFFFFFF)
v6 = matrix[5][b(v5 + v6)] ^ (((v5 + v6) >> 8) & 0xFFFFFF)
v7 = matrix[6][b(v6 + v7)] ^ (((v6 + v7) >> 8) & 0xFFFFFF)
v8 = matrix[7][b(v7 + v8)] ^ (((v7 + v8) >> 8) & 0xFFFFFF)
global output
output = [v1, v2, v3, v4, v5, v6, v7, v8]
def mangle_flag():
# yes, these are supposed to be reversed
v1 = u32(b'yDQ5')
v2 = u32(b'97HD')
v3 = u32(b'Z220')
v4 = u32(b'rUbF')
for i in range(0, 8, 1):
new = v4 ^ user_input[i]
user_input[i] = new
v1 = matrix[0][b(new + v1)] ^ (((new + v1) >> 8) & 0xFFFFFF)
v2 = matrix[1][b(v1 + v2)] ^ (((v1 + v2) >> 8) & 0xFFFFFF)
v3 = matrix[2][b(v2 + v3)] ^ (((v2 + v3) >> 8) & 0xFFFFFF)
v4 = matrix[3][b(v3 + v4)] ^ (((v3 + v4) >> 8) & 0xFFFFFF)
def show():
print(hexdump(user_input, begin=0x64DCA0))
def simulate():
show()
xor_lookup(first_pass=True)
show()
mangle_flag()
show()
xor_lookup(first_pass=False)
show()
# extracted from the binary
target = unhex("617E57049FD9B03B9AB986A2CE6863C66F508493614932C70BB5F5A41B62FCDE")
# dumped memory section
with open("eniptx_000000000064A000.bin", "rb") as f:
f.seek(0x3c60)
# load key and output since they are constant
output = list(map(u32, group(4, f.read(0x20))))
key = list(map(u32, group(4, f.read(0x20))))
# load user_input and split into integers
user_input = list(map(u32, group(4, f.read(0x20))))
# load matrix and split into 8 sub arrays of 256 * sizeof(uint32_t) => 1024 bytes
matrix = group(1024, f.read(1024 * 8))
matrix = [list(map(u32, group(4, subarray))) for subarray in matrix]
if __name__ == "__main__":
simulate()
If you plan to rewrite a challenge like this, double-check that your implementation gives exactly the same results as the original binary! A mistake like this could end up wasting you huge amounts of time.
Now, the first thing that you should notice - output variable is only being assigned to, and it's not used anywhere else. We can remove it without any impact to the result, making code clearer. After that, let's think about how we can inverse the xor_lookup function.
First, let's break it down even further:
matrixis constant, so it's a form of lookup table,- takes one dword of the
user_inputstarting from the end, - XORs it with a dword from
key, - performs a bunch of lookups where each subsequent lookup depends on the previous one,
- uses results of those lookups stored in variables
v1-8to encrypt another dword of theuser_input.
Here's the thing. The first dword of the user_input is trivially recoverable, as it is just XORed with a constant. Since we know the target and the key, we just perform XOR again, and we've got initial data. From there, we know the entire state of this "encryption function". Knowing this, we can perform all lookups to calculate the required v1-8 for the next dword. To calculate v17 we use oldnewuser_input ^ key, old contained dword from the user_input. In our case, the user_input is stored in old, because new contains the result of the encryption).
The inverse function to the xor_lookup looks like this:
def inv_xor_lookup(first_pass: bool) -> None:
v1, v2, v3, v4, v5, v6, v7, v8 = key
if first_pass:
end = 3
else:
end = -1
for i in range(7, end, -1):
old = user_input[i]
new = old ^ v4
user_input[i] = new
v17 = old + v1
# 0xFFFFFF not dword
v1 = matrix[0][b(v17)] ^ ((v17 >> 8) & 0xFFFFFF)
v2 = matrix[1][b(v1 + v2)] ^ (((v1 + v2) >> 8) & 0xFFFFFF)
v3 = matrix[2][b(v2 + v3)] ^ (((v2 + v3) >> 8) & 0xFFFFFF)
v4 = matrix[3][b(v3 + v4)] ^ (((v3 + v4) >> 8) & 0xFFFFFF)
v5 = matrix[4][b(v4 + v5)] ^ (((v4 + v5) >> 8) & 0xFFFFFF)
v6 = matrix[5][b(v5 + v6)] ^ (((v5 + v6) >> 8) & 0xFFFFFF)
v7 = matrix[6][b(v6 + v7)] ^ (((v6 + v7) >> 8) & 0xFFFFFF)
v8 = matrix[7][b(v7 + v8)] ^ (((v7 + v8) >> 8) & 0xFFFFFF)
Now we have to invert the mangle_flag function. Remember the xor_lookup looks awkwardly close to the second mangling stage? Well, that's because it works in the same way - just on a bit different data. We can invert it in the exact same way as the xor_lookup:
def inv_mangle_flag():
# yes, these are supposed to be reversed
v1 = u32(b'yDQ5')
v2 = u32(b'97HD')
v3 = u32(b'Z220')
v4 = u32(b'rUbF')
for i in range(0, 8, 1):
old = user_input[i]
new = v4 ^ old
user_input[i] = new
v1 = matrix[0][b(old + v1)] ^ (((old + v1) >> 8) & 0xFFFFFF)
v2 = matrix[1][b(v1 + v2)] ^ (((v1 + v2) >> 8) & 0xFFFFFF)
v3 = matrix[2][b(v2 + v3)] ^ (((v2 + v3) >> 8) & 0xFFFFFF)
v4 = matrix[3][b(v3 + v4)] ^ (((v3 + v4) >> 8) & 0xFFFFFF)
Now we have to call our inverted functions in reverse order, and we get the flag!
Below is the full solver script and its output:
from pwn import u32, p32, group, unhex, hexdump
from typing import List
key: List[int]
user_input: List[int]
matrix: List[List[int]]
def b(val: int) -> int:
"""cast to byte"""
return val & 0xFF
def d(val: int) -> int:
"""cast to dword"""
return val & 0xFFFFFFFF
def inv_xor_lookup(first_pass: bool) -> None:
v1, v2, v3, v4, v5, v6, v7, v8 = key
if first_pass:
end = 3
else:
end = -1
for i in range(7, end, -1):
old = user_input[i]
new = old ^ v4
user_input[i] = new
v17 = old + v1
# 0xFFFFFF not dword
v1 = matrix[0][b(v17)] ^ ((v17 >> 8) & 0xFFFFFF)
v2 = matrix[1][b(v1 + v2)] ^ (((v1 + v2) >> 8) & 0xFFFFFF)
v3 = matrix[2][b(v2 + v3)] ^ (((v2 + v3) >> 8) & 0xFFFFFF)
v4 = matrix[3][b(v3 + v4)] ^ (((v3 + v4) >> 8) & 0xFFFFFF)
v5 = matrix[4][b(v4 + v5)] ^ (((v4 + v5) >> 8) & 0xFFFFFF)
v6 = matrix[5][b(v5 + v6)] ^ (((v5 + v6) >> 8) & 0xFFFFFF)
v7 = matrix[6][b(v6 + v7)] ^ (((v6 + v7) >> 8) & 0xFFFFFF)
v8 = matrix[7][b(v7 + v8)] ^ (((v7 + v8) >> 8) & 0xFFFFFF)
def inv_mangle_flag():
# yes, these are supposed to be reversed
v1 = u32(b'yDQ5')
v2 = u32(b'97HD')
v3 = u32(b'Z220')
v4 = u32(b'rUbF')
for i in range(0, 8, 1):
old = user_input[i]
new = v4 ^ old
user_input[i] = new
v1 = matrix[0][b(old + v1)] ^ (((old + v1) >> 8) & 0xFFFFFF)
v2 = matrix[1][b(v1 + v2)] ^ (((v1 + v2) >> 8) & 0xFFFFFF)
v3 = matrix[2][b(v2 + v3)] ^ (((v2 + v3) >> 8) & 0xFFFFFF)
v4 = matrix[3][b(v3 + v4)] ^ (((v3 + v4) >> 8) & 0xFFFFFF)
def show():
"""small helper function for debugging"""
print(hexdump(user_input))
# extracted from the binary
target = unhex("617E57049FD9B03B9AB986A2CE6863C66F508493614932C70BB5F5A41B62FCDE")
# dumped memory section
with open("eniptx_000000000064A000.bin", "rb") as f:
f.seek(0x3c60)
output = list(map(u32, group(4, f.read(0x20))))
key = list(map(u32, group(4, f.read(0x20))))
# load user_input and split into integers
user_input = list(map(u32, group(4, f.read(0x20))))
# override user_input with target vector
user_input = list(map(u32, group(4, target)))
# load matrix and split into 8 sub arrays of 256 * sizeof(uint32_t) => 1024 bytes
matrix = group(1024, f.read(1024 * 8))
matrix = [list(map(u32, group(4, subarray))) for subarray in matrix]
show()
inv_xor_lookup(first_pass=False)
show()
inv_mangle_flag()
show()
inv_xor_lookup(first_pass=True)
show()
print("original input:")
print(b"".join(map(lambda x: x[::-1], map(p32, user_input))))
$ python3 solver.py
00000000 61 7e 57 04 9f d9 b0 3b 9a b9 86 a2 ce 68 63 c6 │a~W·│···;│····│·hc·│
00000010 6f 50 84 93 61 49 32 c7 0b b5 f5 a4 1b 62 fc de │oP··│aI2·│····│·b··│
00000020
00000000 13 1d 16 07 bc fb a5 ad 7c 31 ca cd 5b 4c 64 cc │····│····│|1··│[Ld·│
00000010 27 a7 da 6e 91 6e b7 d3 73 dd 28 77 69 37 9e 98 │'··n│·n··│s·(w│i7··│
00000020
00000000 61 48 74 41 54 43 6b 63 65 61 7b 46 66 31 62 32 │aHtA│TCkc│ea{F│f1b2│
00000010 fa 03 94 56 4e 54 fa 58 34 49 02 e9 0f 37 04 72 │···V│NT·X│4I··│·7·r│
00000020
00000000 61 48 74 41 54 43 6b 63 65 61 7b 46 66 31 62 32 │aHtA│TCkc│ea{F│f1b2│
00000010 31 35 61 63 39 34 39 35 35 64 35 65 7d 62 66 34 │15ac│9495│5d5e│}bf4│
00000020
original input:
b'AtHackCTF{ae2b1fca515949e5d54fb}'